
: 함수적 종속성을 이용해 연관된 속성을 분리하고 이상 현상을 방지. 핵심은 테이블을 적절하게 나누는 것이다.
- 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF까지 있다고 함
- 비공식적으로는 3NF까지 되었으면 정규화 되었다고 한다고 함
제 1 정규형
: 중복되는 항목이 없다.
- 보통 아래와 같은 규칙을 적용하면 중복되는 항목이 제거 될 수 있음
- 릴레이션에 속한 모든 속성(attribute)이 원자(atomic) 값으로만 구성되어있도록
- 모든 속성에 반복되는 그룹이 나타나지 않음.(tel1, tel2 이렇게 나타나지 않음)
- 기본 키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 함.
| Customer ID | First Name | Surname | Telephone Number |
|---|---|---|---|
| 123 | Robert | Ingram | 555-861-2025 |
| 456 | Jane | Wright | 555-403-1659 555-776-4100 555-123-4567 |
| 789 | Maria | Fernandez | 555-808-9633 |
위의 경우 Tel 항목에는 여러 값을 두게 되는데, 1NF(RDBMS에서도 마찬가지로)에서는 행 도메인에서 한개의 값만을 허용함. 따라서, 1번을 위반해 아래와 같이 변경
| Customer ID | First Name | Surname | Tel. No. 1 | Tel. No. 2 | Tel. No. 3 |
|---|---|---|---|---|---|
| 123 | Robert | Ingram | 555-861-2025 | ||
| 456 | Jane | Wright | 555-403-1659 | 555-776-4100 | 555-123-4567 |
| 789 | Maria | Fernandez | 555-808-9633 |
값이 없는 곳에는 Null값을 가질 수 있지만 Tel 정보가 세개나 들어가게 되고, 2번 규칙을 위반함으로써 이와같은 문제가 발생할 수 있다. 1. “전화번호 네개 있는 경우 저장을 못함”, 2. “동일한 값이 들어가는 경우가 발생”
| Customer ID | First Name | Surname | Telephone Number |
|---|---|---|---|
| 123 | Robert | Ingram | 555-861-2025 |
| 456 | Jane | Wright | 555-403-1659, 555-776-4100, 555-123-4567 |
| 789 | Maria | Fernandez | 555-808-9633 |
그런다고 위와같이 여러 전화번호를 하나의 값으로 저장할 수 있도록 하면 의미상으로 모호해져서, “전화번호”를 표현할 수도, “전화번호 리스트”를 표현할 수도 있다.
- 1NF를 충족하는 디자인: 두개의 테이블로 나눠서 관리하는 것
| Customer ID | First Name | Surname |
|---|---|---|
| 123 | Robert | Ingram |
| 456 | Jane | Wright |
| 789 | Maria | Fernandez |
| Customer ID | Telephone Number |
|---|---|
| 123 | 555-861-2025 |
| 456 | 555-403-1659 |
| 456 | 555-776-4100 |
| 456 | 555-123-4567 |
| 789 | 555-808-9633 |
그러나, 이게 해결된다고 이상 현상이 항상 없지는 않다.
제 2 정규형
: 제 1 정규형을 만족하고, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속성을 가진다.
| STUDENT_ID | COURSE_ID | PROFESSOR_NAME | GRADE | STUDENT_NAME |
|---|---|---|---|---|
| 1 | OS123 | 김ㅇㅇ | B | 김ㅇㅇ |
| 1 | ALG123 | 권ㅇㅇ | F | 김ㅇㅇ |
| 2 | ALG123 | 권ㅇㅇ | A | 이ㅇㅇ |
| 3 | NET123 | 최ㅇㅇ | B+ | 최ㅇㅇ |
| 4 | OS123 | 김ㅇㅇ | A+ | 손ㅇㅇ |
위의 경우
학번 -> 이름과수업 -> 교수의 경우 부분함수 종속이 된다.아래와 같은 방법으로 나누면 됨
![부분 함수 종속]()
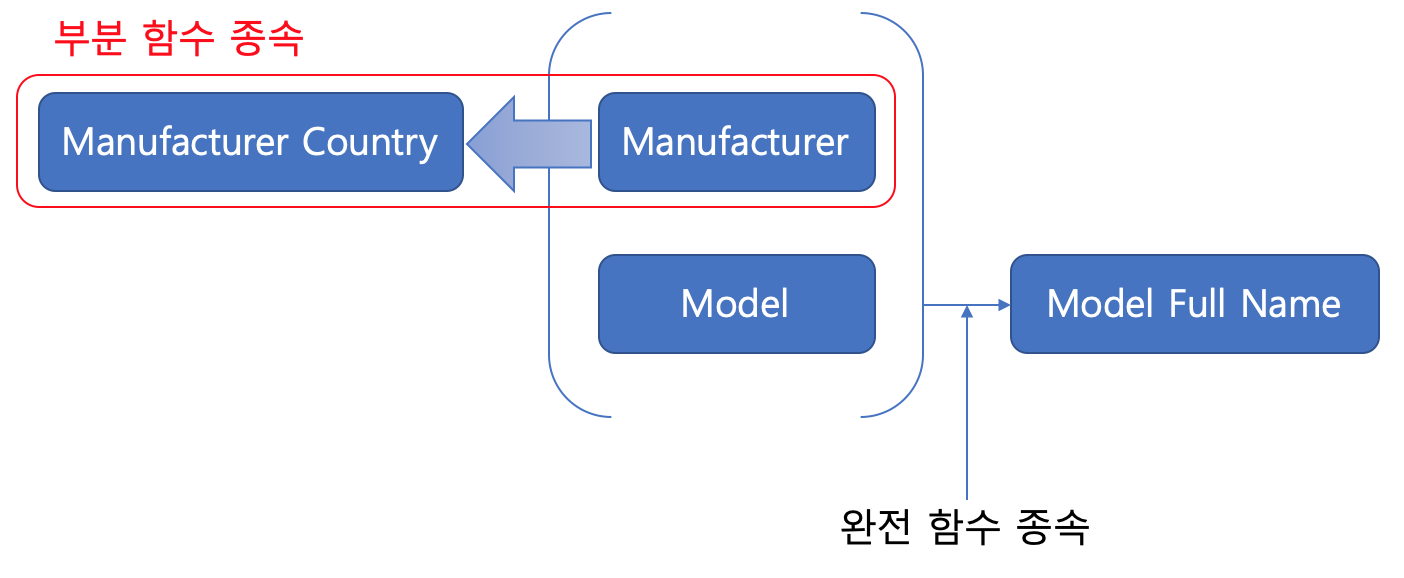
- 이러한 규칙대로라면, { 학번, 수업, 성적 }, { 수업, 교수 }, { 학번, 학생 이름 } 테이블로 나뉠 것.
- 그러나, 마찬가지로 이게 해결된다고 이상 현상이 항상 없지는 않다.
제 3 정규형
: 제 2 정규형에 속하면서, 기본 키가 아닌 속성은 기본 키에만 의존해야 한다.
| STUDENT_ID | COURSE_ID | SCORE | GRADE |
|---|---|---|---|
| 1 | OS123 | 80 | B |
| 1 | ALG123 | 30 | F |
| 2 | ALG123 | 90 | A |
- 이 테이블의 경우 기본키는 { 학생, 수업 }인데, grade는 score에 따라 달라진다.
- X -> Y 이고 Y -> Z 이면 X -> Z가 성립할 때가 이 경우에 속한다.
- 이걸 둘로 분리해주면 됨. { 학번, 수업, 점수 }, { 점수, 학점 }
- 마찬가지로 여전히 이상 현생은 발생할 수 있다.
BCNF(Boyce Codd Normal Form)
: 모든 결정자는 Key여야 한다. 즉, “결정자이면서 후보키가 아닌 것”을 제거해야한다.
- 아래의 경우 (한 교수는 한 과목만 맡는다고 할 때)
{ 학번, 과목 }이 기본키(후보키) 이지만, 교수가 과목을 결정하는결정자가 된다.
| 학번 | 과목 | 교수 |
|---|---|---|
| 100 | 데이터베이스 | 홍길동 |
| 100 | 자료구조 | 임꺽정 |
| 200 | 네트워크 | 장영실 |
| 300 | 인공지능 | 유관순 |
- 갱신 이상: 교수가 과목 이름을 바꾸면 해당 교수의 과목을 다 바꿔야 한다.
- 삽입 이상: 200 학생이 데이터베이스를 수강하고자 할 때 현재 불필요한 홍길동 교수가 한번 더 삽입된다.
- 삭제 이상: 300학생이 자퇴해서 사라진다고 할 때 인공지능, 유관순 정보도 함께 사라진다.
-> { 학번, 학수번호 }, { 학수번호, 과목, 교수 } 테이블로 변경해 해결
Reference)
https://ko.wikipedia.org/wiki/%EC%A0%9C1%EC%A0%95%EA%B7%9C%ED%98%95
https://yaboong.github.io/database/2018/03/09/database-anomaly-and-functional-dependency/
https://wkdtjsgur100.github.io/database-normalization/
https://nirsa.tistory.com/107